
MNT Reform 2 - part deux
A few days back I posted some of my initial thoughts of the MNT Reform 2 laptop which just recently arrived. I ran the usual battery of tests on the laptop including the High Performance Linpack (HPL) of course just for kicks.
At that time, I made no attempt to optmize HPL. I simply went with the OS supplied gcc and math libraries. My next step was to look at how I could improve my HPL result using the Arm compiler for Linux and the Arm performance libraries. Here I’ll walk through those steps from installing the Arm tools, to compiling and running HPL - and all of the small details in between.
(1) To start, I downloaded the latest verion of the Arm compiler for Linux package from here. This was the package with the filename: arm-compiler-for-linux_22.0.2_Ubuntu-20.04_aarch64.tar.
(2) After uncompressing arm-compiler-for-linux_22.0.2_Ubuntu-20.04_aarch64.tar, I ran the installation command ./arm-compiler-for-linux_22.0.2_Ubuntu-20.04.sh -a which installed the software to /opt/arm on the system. Note that the Arm compilers for Linux ship with module files to make setting up the envionment for compiling easy. To support this I had to install the OS environment-modules package with apt-get install environment-modules
(3) In order to load the module for the Arm compiler for Linux, the following steps are necessary. This assumes that the Arm compiler for Linux is installed in /opt/arm.
root@reform:/# module avail
----------------------------------- /usr/share/modules/modulefiles ------------------------------------
dot module-git module-info modules null use.own
Key:
modulepath
root@reform:/# export MODULEPATH=/opt/arm/modulefiles:$MODULEPATH
root@reform:/# module avail
---------------------------------------- /opt/arm/modulefiles -----------------------------------------
acfl/22.0.2 binutils/11.2.0 gnu/11.2.0
----------------------------------- /usr/share/modules/modulefiles ------------------------------------
dot module-git module-info modules null use.own
Key:
modulepath
root@reform:/# module load acfl/22.0.2
Loading acfl/22.0.2
Loading requirement: binutils/11.2.0
root@reform:/# echo $PATH
/opt/arm/arm-linux-compiler-22.0.2_Generic-AArch64_Ubuntu-20.04_aarch64-linux/bin:/opt/arm/gcc-11.2.0_Generic-AArch64_Ubuntu-20.04_aarch64-linux/binutils_bin:/root/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root@reform:/# armclang --version
Arm C/C++/Fortran Compiler version 22.0.2 (build number 1776) (based on LLVM 13.0.0)
Target: aarch64-unknown-linux-gnu
Thread model: posix
InstalledDir: /opt/arm/arm-linux-compiler-22.0.2_Generic-AArch64_Ubuntu-20.04_aarch64-linux/bin(4) Now we shift our focus to Open MPI. Open MPI is an open source distribution of the message passing interface (MPI) library for writing parallel applications. We will compile HPL against this Open MPI version. For this, I downloaded the latest Open MPI version (4.1.4) from here.
By default, Open MPI compiles with support for the SLURM workload manager. My Reform has IBM Spectrum LSF installed as the workload scheduler. In order to enable LSF support in Open MPI, we need to specify the appropriate configure flags (see below).
root@reform:/opt/HPC/openmpi-4.1.4# ./configure --prefix=/opt/HPC/openmpi-4.1.4 --with-lsf=/opt/ibm/lsf/10.1 --with-lsf-libdir=/opt/ibm/lsf/10.1/linux3.12-glibc2.17-armv8/lib
root@reform:/opt/HPC/openmpi-4.1.4# make -j 4
...
...
root@reform:/opt/HPC/openmpi-4.1.4# make install
...
...(5) After completing the compilation of Open MPI, the ompi_info command is run to check if support for LSF has been enabled. Note that you must ensure to source the LSF environment (i.e. . ./profile.lsf) before running ompi_info or the LSF libraries won’t be found.
root@reform:/opt/HPC/openmpi-4.1.4# ./bin/ompi_info |grep -i lsf
Configure command line: '--prefix=/opt/HPC/openmpi-4.1.4' '--with-lsf=/opt/ibm/lsf/10.1' '--with-lsf-libdir=/opt/ibm/lsf/10.1/linux3.12-glibc2.17-armv8/lib'
MCA ess: lsf (MCA v2.1.0, API v3.0.0, Component v4.1.4)
MCA plm: lsf (MCA v2.1.0, API v2.0.0, Component v4.1.4)
MCA ras: lsf (MCA v2.1.0, API v2.0.0, Component v4.1.4)(6) Next, I downloaded the latest HPL package from here. I uncompressed the the package hpl-2.3.tar.gz in the /opt/HPC directory. Next, I had to create a new Makefile for HPL which would use the Arm compiler for Linux and optmized math libraries. A copy of Make.imx8qm follows below.
#
# -- High Performance Computing Linpack Benchmark (HPL)
# HPL - 2.3 - December 2, 2018
# Antoine P. Petitet
# University of Tennessee, Knoxville
# Innovative Computing Laboratory
# (C) Copyright 2000-2008 All Rights Reserved
#
# -- Copyright notice and Licensing terms:
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
#
# 1. Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
#
# 2. Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions, and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
#
# 3. All advertising materials mentioning features or use of this
# software must display the following acknowledgement:
# This product includes software developed at the University of
# Tennessee, Knoxville, Innovative Computing Laboratory.
#
# 4. The name of the University, the name of the Laboratory, or the
# names of its contributors may not be used to endorse or promote
# products derived from this software without specific written
# permission.
#
# -- Disclaimer:
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
# ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
# A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE UNIVERSITY
# OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
# DATA OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# ######################################################################
#
# ----------------------------------------------------------------------
# - shell --------------------------------------------------------------
# ----------------------------------------------------------------------
#
SHELL = /bin/sh
#
CD = cd
CP = cp
LN_S = ln -s
MKDIR = mkdir
RM = /bin/rm -f
TOUCH = touch
#
# ----------------------------------------------------------------------
# - Platform identifier ------------------------------------------------
# ----------------------------------------------------------------------
#
ARCH = imx8qm
#
# ----------------------------------------------------------------------
# - HPL Directory Structure / HPL library ------------------------------
# ----------------------------------------------------------------------
#
TOPdir = /opt/HPC/hpl-2.3
INCdir = /opt/HPC/hpl-2.3/include
BINdir = /opt/HPC/hpl-2.3/bin/$(ARCH)
LIBdir = /opt/HPC/hpl-2.3/lib/$(ARCH)
#
HPLlib = /opt/HPC/hpl-2.3/lib/libhpl.a
#
# ----------------------------------------------------------------------
# - Message Passing library (MPI) --------------------------------------
# ----------------------------------------------------------------------
# MPinc tells the C compiler where to find the Message Passing library
# header files, MPlib is defined to be the name of the library to be
# used. The variable MPdir is only used for defining MPinc and MPlib.
#
MPdir = /opt/HPC/openmpi-4.1.4
MPinc = /opt/HPC/openmpi-4.1.4/include
MPlib = /opt/HPC/openmpi-4.1.4/lib/libmpi.so
#
# ----------------------------------------------------------------------
# - Linear Algebra library (BLAS or VSIPL) -----------------------------
# ----------------------------------------------------------------------
# LAinc tells the C compiler where to find the Linear Algebra library
# header files, LAlib is defined to be the name of the library to be
# used. The variable LAdir is only used for defining LAinc and LAlib.
#
LAdir =
LAinc =
# LAlib = -lamath -lm -mcpu=native
LAlib =
#
# ----------------------------------------------------------------------
# - F77 / C interface --------------------------------------------------
# ----------------------------------------------------------------------
# You can skip this section if and only if you are not planning to use
# a BLAS library featuring a Fortran 77 interface. Otherwise, it is
# necessary to fill out the F2CDEFS variable with the appropriate
# options. **One and only one** option should be chosen in **each** of
# the 3 following categories:
#
# 1) name space (How C calls a Fortran 77 routine)
#
# -DAdd_ : all lower case and a suffixed underscore (Suns,
# Intel, ...), [default]
# -DNoChange : all lower case (IBM RS6000),
# -DUpCase : all upper case (Cray),
# -DAdd__ : the FORTRAN compiler in use is f2c.
#
# 2) C and Fortran 77 integer mapping
#
# -DF77_INTEGER=int : Fortran 77 INTEGER is a C int, [default]
# -DF77_INTEGER=long : Fortran 77 INTEGER is a C long,
# -DF77_INTEGER=short : Fortran 77 INTEGER is a C short.
#
# 3) Fortran 77 string handling
#
# -DStringSunStyle : The string address is passed at the string loca-
# tion on the stack, and the string length is then
# passed as an F77_INTEGER after all explicit
# stack arguments, [default]
# -DStringStructPtr : The address of a structure is passed by a
# Fortran 77 string, and the structure is of the
# form: struct {char *cp; F77_INTEGER len;},
# -DStringStructVal : A structure is passed by value for each Fortran
# 77 string, and the structure is of the form:
# struct {char *cp; F77_INTEGER len;},
# -DStringCrayStyle : Special option for Cray machines, which uses
# Cray fcd (fortran character descriptor) for
# interoperation.
#
F2CDEFS =
#
# ----------------------------------------------------------------------
# - HPL includes / libraries / specifics -------------------------------
# ----------------------------------------------------------------------
#
HPL_INCLUDES = -I$(INCdir) -I$(INCdir)/$(ARCH) $(LAinc) -I$(MPinc) -I/opt/arm/armpl-22.0.2_AArch64_Ubuntu-20.04_gcc_aarch64-linux/include/
HPL_LIBS = $(HPLlib) $(LAlib) $(MPlib)
#
# - Compile time options -----------------------------------------------
#
# -DHPL_COPY_L force the copy of the panel L before bcast;
# -DHPL_CALL_CBLAS call the cblas interface;
# -DHPL_CALL_VSIPL call the vsip library;
# -DHPL_DETAILED_TIMING enable detailed timers;
#
# By default HPL will:
# *) not copy L before broadcast,
# *) call the BLAS Fortran 77 interface,
# *) not display detailed timing information.
#
HPL_OPTS =
#
# ----------------------------------------------------------------------
#
HPL_DEFS = $(F2CDEFS) $(HPL_OPTS) $(HPL_INCLUDES)
#
# ----------------------------------------------------------------------
# - Compilers / linkers - Optimization flags ---------------------------
# ----------------------------------------------------------------------
#
CC = armclang
CCNOOPT = $(HPL_DEFS)
CCFLAGS = $(HPL_DEFS) -O3 -larmpl_lp64 -lamath -lm
#
LINKER = armclang -O3 -armpl -lamath -lm
LINKFLAGS = $(CCFLAGS)
#
ARCHIVER = ar
ARFLAGS = r
RANLIB = echo
#
# ----------------------------------------------------------------------(7) To compile HPL with the above Makefile is as simple as running the appropriate make command and specify the architecture imx8qm.
root@reform:/opt/HPC/hpl-2.3# make arch=imx8qm
...
...(8) Barring any errors, we should now have an xhpl binary in under the /opt/HPC/hpl-2.3/bin/imx8qm directory.
root@reform:/opt/HPC/hpl-2.3/bin/imx8qm# pwd
/opt/HPC/hpl-2.3/bin/imx8qm
root@reform:/opt/HPC/hpl-2.3/bin/imx8qm# ls -la
total 156
drwxr-xr-x 2 root root 4096 Jun 8 13:30 .
drwxr-xr-x 3 root root 4096 Jun 8 13:20 ..
-rw-r--r-- 1 root root 1454 Jun 8 13:30 HPL.dat
-rwxr-xr-x 1 root root 146960 Jun 8 13:24 xhpl
root@reform:/opt/HPC/hpl-2.3/bin/imx8qm# ldd ./xhpl
linux-vdso.so.1 (0x0000007faa7b1000)
libamath_aarch64.so => /opt/arm/arm-linux-compiler-22.0.2_Generic-AArch64_Ubuntu-20.04_aarch64-linux/llvm-bin/../lib/libamath_aarch64.so (0x0000007faa5ef000)
libm.so.6 => /lib/aarch64-linux-gnu/libm.so.6 (0x0000007faa520000)
libarmpl_lp64.so => /opt/arm/arm-linux-compiler-22.0.2_Generic-AArch64_Ubuntu-20.04_aarch64-linux/lib/clang/13.0.0/armpl_links/lib/libarmpl_lp64.so (0x0000007fa3cd5000)
libmpi.so.40 => /usr/lib/aarch64-linux-gnu/libmpi.so.40 (0x0000007fa3b8f000)
libarmflang.so => /opt/arm/arm-linux-compiler-22.0.2_Generic-AArch64_Ubuntu-20.04_aarch64-linux/llvm-bin/../lib/libarmflang.so (0x0000007fa3728000)
libomp.so => /opt/arm/arm-linux-compiler-22.0.2_Generic-AArch64_Ubuntu-20.04_aarch64-linux/llvm-bin/../lib/libomp.so (0x0000007fa3649000)
librt.so.1 => /lib/aarch64-linux-gnu/librt.so.1 (0x0000007fa3631000)
libdl.so.2 => /lib/aarch64-linux-gnu/libdl.so.2 (0x0000007fa361d000)
libpthread.so.0 => /lib/aarch64-linux-gnu/libpthread.so.0 (0x0000007fa35ed000)
libastring_aarch64.so => /opt/arm/arm-linux-compiler-22.0.2_Generic-AArch64_Ubuntu-20.04_aarch64-linux/llvm-bin/../lib/libastring_aarch64.so (0x0000007fa35da000)
libc.so.6 => /lib/aarch64-linux-gnu/libc.so.6 (0x0000007fa345f000)
/lib/ld-linux-aarch64.so.1 (0x0000007faa77e000)
libgcc_s.so.1 => /opt/arm/gcc-11.2.0_Generic-AArch64_Ubuntu-20.04_aarch64-linux/lib64/libgcc_s.so.1 (0x0000007fa343a000)
libopen-rte.so.40 => /usr/lib/aarch64-linux-gnu/libopen-rte.so.40 (0x0000007fa336c000)
libopen-pal.so.40 => /usr/lib/aarch64-linux-gnu/libopen-pal.so.40 (0x0000007fa32aa000)
libhwloc.so.15 => /usr/lib/aarch64-linux-gnu/libhwloc.so.15 (0x0000007fa3245000)
libstdc++.so.6 => /opt/arm/gcc-11.2.0_Generic-AArch64_Ubuntu-20.04_aarch64-linux/lib64/libstdc++.so.6 (0x0000007fa3030000)
libz.so.1 => /lib/aarch64-linux-gnu/libz.so.1 (0x0000007fa3006000)
libevent_core-2.1.so.7 => /usr/lib/aarch64-linux-gnu/libevent_core-2.1.so.7 (0x0000007fa2fbf000)
libutil.so.1 => /lib/aarch64-linux-gnu/libutil.so.1 (0x0000007fa2fab000)
libevent_pthreads-2.1.so.7 => /usr/lib/aarch64-linux-gnu/libevent_pthreads-2.1.so.7 (0x0000007fa2f98000)
libudev.so.1 => /usr/lib/aarch64-linux-gnu/libudev.so.1 (0x0000007fa2f5e000)(9) A default HPL.dat file should ber present in the directory /opt/HPC/hpl-2.3/bin/imx8qm. The file HPL.dat is used to tune the benchmark problem size according to the system. A copy of the HPL.dat file I created follows below. This is suitable for the 4 GB memory configuration of Reform with 4 processor cores.
HPLinpack benchmark input file
Innovative Computing Laboratory, University of Tennessee
HPL.out output file name (if any)
6 device out (6=stdout,7=stderr,file)
1 # of problems sizes (N)
19000 Ns
1 # of NBs
192 NBs
0 PMAP process mapping (0=Row-,1=Column-major)
1 # of process grids (P x Q)
2 Ps
2 Qs
16.0 threshold
1 # of panel fact
2 PFACTs (0=left, 1=Crout, 2=Right)
1 # of recursive stopping criterium
4 NBMINs (>= 1)
1 # of panels in recursion
2 NDIVs
1 # of recursive panel fact.
1 RFACTs (0=left, 1=Crout, 2=Right)
1 # of broadcast
1 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)
1 # of lookahead depth
1 DEPTHs (>=0)
2 SWAP (0=bin-exch,1=long,2=mix)
64 swapping threshold
0 L1 in (0=transposed,1=no-transposed) form
0 U in (0=transposed,1=no-transposed) form
1 Equilibration (0=no,1=yes)
8 memory alignment in double (> 0)
##### This line (no. 32) is ignored (it serves as a separator). ######
0 Number of additional problem sizes for PTRANS
1200 10000 30000 values of N
0 number of additional blocking sizes for PTRANS
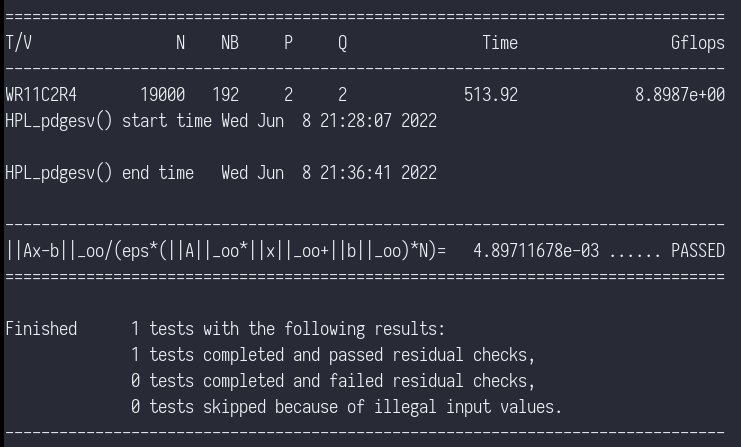
40 9 8 13 13 20 16 32 64 values of NB(10) Now we’re ready to execute the appropriate mpirun command to run the xhpl executable. We specify -np 4 to run across the 4 cores of the processor. With this better optimized run we’re seeing ~8.9 GFLOPS performance compared with ~4 GFLOPS for my previous runs where HPL was compiled with the OS supplied GCC and Math libraries (ATLAS). Note that as this is roughly double the GFLOPS from my previous runs, it appears that there is an issue with double precision or perhaps vectorization with the non-optimized runs.
gsamu@reform:/opt/HPC/hpl-2.3/bin/imx8qm$ mpirun -np 4 ./xhpl
================================================================================
HPLinpack 2.3 -- High-Performance Linpack benchmark -- December 2, 2018
Written by A. Petitet and R. Clint Whaley, Innovative Computing Laboratory, UTK
Modified by Piotr Luszczek, Innovative Computing Laboratory, UTK
Modified by Julien Langou, University of Colorado Denver
================================================================================
An explanation of the input/output parameters follows:
T/V : Wall time / encoded variant.
N : The order of the coefficient matrix A.
NB : The partitioning blocking factor.
P : The number of process rows.
Q : The number of process columns.
Time : Time in seconds to solve the linear system.
Gflops : Rate of execution for solving the linear system.
The following parameter values will be used:
N : 19000
NB : 192
PMAP : Row-major process mapping
P : 2
Q : 2
PFACT : Right
NBMIN : 4
NDIV : 2
RFACT : Crout
BCAST : 1ringM
DEPTH : 1
SWAP : Mix (threshold = 64)
L1 : transposed form
U : transposed form
EQUIL : yes
ALIGN : 8 double precision words
--------------------------------------------------------------------------------
- The matrix A is randomly generated for each test.
- The following scaled residual check will be computed:
||Ax-b||_oo / ( eps * ( || x ||_oo * || A ||_oo + || b ||_oo ) * N )
- The relative machine precision (eps) is taken to be 1.110223e-16
- Computational tests pass if scaled residuals are less than 16.0
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR11C2R4 19000 192 2 2 513.92 8.8987e+00
HPL_pdgesv() start time Wed Jun 8 21:28:07 2022
HPL_pdgesv() end time Wed Jun 8 21:36:41 2022
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 4.89711678e-03 ...... PASSED
================================================================================
Finished 1 tests with the following results:
1 tests completed and passed residual checks,
0 tests completed and failed residual checks,
0 tests skipped because of illegal input values.
--------------------------------------------------------------------------------
End of Tests.
================================================================================(11) Finally, we submit the same run of Linpack but through Spectrum LSF. The LSF bsub command invocation is shown below and the resulting output.
gsamu@reform:~$ bsub -n 4 -I -m reform "cd /opt/HPC/hpl-2.3/bin/imx8qm ; mpirun ./xhpl"
Job <35301> is submitted to default queue <interactive>.
<<Waiting for dispatch ...>>
<<Starting on reform>>
================================================================================
HPLinpack 2.3 -- High-Performance Linpack benchmark -- December 2, 2018
Written by A. Petitet and R. Clint Whaley, Innovative Computing Laboratory, UTK
Modified by Piotr Luszczek, Innovative Computing Laboratory, UTK
Modified by Julien Langou, University of Colorado Denver
================================================================================
An explanation of the input/output parameters follows:
T/V : Wall time / encoded variant.
N : The order of the coefficient matrix A.
NB : The partitioning blocking factor.
P : The number of process rows.
Q : The number of process columns.
Time : Time in seconds to solve the linear system.
Gflops : Rate of execution for solving the linear system.
The following parameter values will be used:
N : 19000
NB : 192
PMAP : Row-major process mapping
P : 2
Q : 2
PFACT : Right
NBMIN : 4
NDIV : 2
RFACT : Crout
BCAST : 1ringM
DEPTH : 1
SWAP : Mix (threshold = 64)
L1 : transposed form
U : transposed form
EQUIL : yes
ALIGN : 8 double precision words
--------------------------------------------------------------------------------
- The matrix A is randomly generated for each test.
- The following scaled residual check will be computed:
||Ax-b||_oo / ( eps * ( || x ||_oo * || A ||_oo + || b ||_oo ) * N )
- The relative machine precision (eps) is taken to be 1.110223e-16
- Computational tests pass if scaled residuals are less than 16.0
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR11C2R4 19000 192 2 2 518.02 8.8283e+00
HPL_pdgesv() start time Thu Jun 9 09:33:35 2022
HPL_pdgesv() end time Thu Jun 9 09:42:13 2022
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 4.89711678e-03 ...... PASSED
================================================================================
Finished 1 tests with the following results:
1 tests completed and passed residual checks,
0 tests completed and failed residual checks,
0 tests skipped because of illegal input values.
--------------------------------------------------------------------------------
End of Tests.
================================================================================