
Hello operator. I need an HPC cluster – fast
As users of HPC look to build new workflows that go beyond traditional simulation and modeling, cloud native development models that rely upon Kubernetes (K8s) and Docker are front of mind. K8s provides the framework and a large ecosystem of key applications and technologies which can help to facilitate this transformation of HPC. This naturally leads to HPC centers looking at approaches to use their infrastructure to run their traditional HPC workloads alongside K8s workloads.
To this end, there is an available K8s/OpenShift integration with IBM Spectrum LSF which is available as a tech preview on the Spectrum Computing github. There are a few parts to the integration. Firstly, LSF can act as a scheduler for K8s/OpenShift pods. Secondly an operator is available, that makes it easy to deploy an LSF cluster on top of a K8s/OpenShift cluster. Note that the integration is a technical preview.
It is the K8s operator for LSF that is the focus of this writeup. For those of you who have been following me on Twitter, you’ll be aware that I’ve been tinkering with the Spectrum LSF K8s operator on and off for about a year now.
Even though Canadian Thanksgiving is a month behind us,
— Gábor SAMU (@gabor_samu) November 26, 2020
I'm definitely feeling the vibe from US #Thanksgiving. Rockin' Spectrum LSF on #OpenShift on #IBMCloud - while listening to Santana. Get your LSF #k8s operator here! https://t.co/p5V7sMg6ic #Thankful #HPC
This December I’ve had the opportunity to revisit the K8s operator for LSF. The motivation in this case, was the need to quickly spin up LSF test clusters in order to run some Intel MPI workloads. And as we’ll see, although getting the LSF clusters spun up on demand using the operator is very straightforward, a bit of fine tuning was needed in order to be able to successfully run the Intel MPI workloads.
The github page where the K8s/OpenShift and Spectrum LSF integration is hosted contains documentation on how to setup the operator and deploy an LSF cluster on K8s/OpenShift. Spinning up the LSF cluster is quite simple, once you’ve followed the steps in the above noted documentation. We’ve configured the deployment to include an LSF management pod, and 4 LSF compute pods. LSF Suite for HPC v10.2.0.11 is the version that was deployed. And the target OpenShift cluster is hosted in the IBM Cloud.
After authenticating with the OpenShift cluster, using the OpenShift oc command line, I could spin up an LSF cluster with a single command from my laptop as follows:
$ oc create -f ./lsfcluster.yaml
lsfcluster.lsf.spectrumcomputing.ibm.com/example-lsfcluster createdAnd after a few moments, we see the one management pod, and four compute pods. There is a slight delay to start the pods as there are some dependencies on PVCs (storage) which need to be created first by the operator.
$ oc get pods
NAME READY STATUS RESTARTS AGE
ibm-lsf-operator-66bd9449c-5lzmx 2/2 Running 0 21h
lsfcluster-master-68f954645-j8v2v 1/1 Running 0 5m27s
lsfcluster-rhel7-fcdcf8559-d6955 1/1 Running 0 5m29s
lsfcluster-rhel7-fcdcf8559-h5pqb 1/1 Running 0 5m29s
lsfcluster-rhel7-fcdcf8559-xkld7 1/1 Running 0 5m28s
lsfcluster-rhel7-fcdcf8559-zmgzp 1/1 Running 0 5m29sConnecting to the pods is straightforward and we’ve run a few commands to show that the LSF cluster is operational.
$ oc exec -ti lsfcluster-rhel7-fcdcf8559-d6955 -- /bin/bash
LSF POD [root:/]# lsid
IBM Spectrum LSF 10.1.0.11, Nov 12 2020
Suite Edition: IBM Spectrum LSF Suite for HPC 10.2.0.11
Copyright International Business Machines Corp. 1992, 2016.
US Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.
My cluster name is lsfcluster
My master name is lsfmaster
LSF POD [root:/]# lsload -w
HOST_NAME status r15s r1m r15m ut pg ls it tmp swp mem
lsfcluster-rhel7-fcdcf8559-h5pqb ok 0.2 0.1 0.9 3% 0.0 0 14 89G 7.4G 7.4G
lsfcluster-rhel7-fcdcf8559-xkld7 ok 1.5 1.2 0.8 3% 0.0 0 14 83G 7.4G 7.4G
lsfcluster-rhel7-fcdcf8559-zmgzp ok 2.1 0.6 0.8 3% 0.0 0 14 85G 7.4G 7.4G
lsfmaster ok 3.3 0.1 0.7 3% 0.0 0 3e+5 83G 786.8M 785M
lsfcluster-rhel7-fcdcf8559-d6955 ok 15.2 0.2 1.0 2% 0.0 0 3e+5 89G 7.4G 7.4GIntel MPI is integrated with a number of different HPC job schedulers including LSF. More details on this can be found here. And you can find some tips on submitting Intel MPI jobs to LSF at in the documentation here. Intel MPI integrates with the LSF blaunch framework to launch tasks on hosts. The Intel MPI version which used is that which is bundled with current (at the time of writing) Intel oneAPI, which I installed from the online repos using the procedure here. The specific Intel oneAPI packages installed are: intel-hpckit-runtime-2021.4.0.x86_64, and intel-oneapi-clck.x86_64.
By default, Intel oneAPI is installed to the directory /opt/intel/oneapi. To use the tools you must first source setvars.sh.
# . /opt/intel/oneapi/setvars.sh
:: initializing oneAPI environment ...
bash: BASH_VERSION = 4.2.46(2)-release
args: Using "$@" for setvars.sh arguments:
:: clck -- latest
:: compiler -- latest
:: dev-utilities -- latest
:: dnnl -- latest
:: mpi -- latest
:: tbb -- latest
:: oneAPI environment initialized ::Intel Cluster Checker (RPM) includes an example mpi_hello_world binary located in /opt/intel/oneapi/clck/2021.5.0/provider/share/mpi_internode. Let’s first check that we can run the MPI Hello World example outside of LSF. Running a single rank works.
# mpirun -n 1 ./mpi_hello_world
Hello world: rank 0 of 1 running on lsfcluster-rhel7-fcdcf8559-zmgzpHowever, trying to run > 1 rank on a single node fails with SIGBUS (Bus error).
# mpirun -n 4 ./mpi_hello_world
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= RANK 0 PID 10582 RUNNING AT lsfcluster-rhel7-fcdcf8559-zmgzp
= KILLED BY SIGNAL: 7 (Bus error)
===================================================================================
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= RANK 1 PID 10583 RUNNING AT lsfcluster-rhel7-fcdcf8559-zmgzp
= KILLED BY SIGNAL: 7 (Bus error)
===================================================================================
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= RANK 2 PID 10584 RUNNING AT lsfcluster-rhel7-fcdcf8559-zmgzp
= KILLED BY SIGNAL: 7 (Bus error)
===================================================================================
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= RANK 3 PID 10585 RUNNING AT lsfcluster-rhel7-fcdcf8559-zmgzp
= KILLED BY SIGNAL: 7 (Bus error)
===================================================================================As it turns out, this is related to the shared memory size configured for the pods. The default shared memory size is 64MB in the pods. This is also documented for MPICH here. Checking the shared memory size on the compute pod showed a value of 64MB.
# mount |grep shm
shm on /dev/shm type tmpfs (rw,nosuid,nodev,noexec,relatime,context="system_u:object_r:container_file_t:s0:c102,c977",size=65536k)From this, we deduce that the solution is to increase the shmem size. On the surface, this seemed like something straightforward to do. Indeed, there is a documented procedure on the OpenShift page here to achive this.
However, the above steps don’t work if the changes are made to the deployment file and a new LSF cluster is created. The LSF operator tries to create a PVC for a volume of type emptyDir and the deployment stalls waiting on this (which can never happen). The LSF operator should not try to create a PVC in this case. Rather it should simply add the Volumes and VolumeMounts as described in the OpenShift shared memory guide above. Note that I have given this feedback to the fine folks who maintain the LSF operator.
It is possible though to edit an existing deployment to add to the volumes and volumeMounts required to increase the shared memory for the pods.
$ oc get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
ibm-lsf-operator 1/1 1 1 13d
lsfcluster-master 1/1 1 1 3h4m
lsfcluster-rhel7 4/4 4 4 3h4mAs we’ll only be running MPI jobs on the compute nodes, we only need to edit the deployment lsfcluster-rhel4 for which there are 4 pods running. Using the oc tool, edit the deployment and make the following updates:
oc edit deploy lsfcluster-rhel7
(Note: This starts an editor where you need to add the following - see bolded).
deployment.apps/lsfcluster-rhel7 editedWhat to add while doing the deployment editing above.
...
volumeMounts:
- mountPath: /tmp/.myCluster.sbd
name: sbatchd-volume
- mountPath: /home
name: home
- mountPath: /apps
name: applications
**- mountPath: /dev/shm
name: dshm**
...
volumes:
**- emptyDir:
medium: Memory
name: dshm**
- emptyDir: {}
name: sbatchd-volume
- name: home
persistentVolumeClaim:
claimName: lsfcluster-home
- name: applications
persistentVolumeClaim:
claimName: lsfcluster-applicationsOpenShift will now create the 4 new requested deployments based upon the above updates. That being said, OpenShift will try to keep half of the pods active (2 out of 4 in this case) as it creates the new deployment.
$ oc get pods
NAME READY STATUS RESTARTS AGE
ibm-lsf-operator-66bd9449c-5lzmx 2/2 Running 0 24h
lsfcluster-master-68f954645-j8v2v 1/1 Running 0 3h11m
lsfcluster-rhel7-6577566b87-8jsvc 0/1 Running 0 11s
lsfcluster-rhel7-6577566b87-fhwtt 0/1 Running 0 14s
lsfcluster-rhel7-6577566b87-nxkp4 1/1 Running 0 2m28s
lsfcluster-rhel7-6577566b87-ppxm9 1/1 Running 0 2m28s
lsfcluster-rhel7-fcdcf8559-d6955 1/1 Terminating 0 3h11m
lsfcluster-rhel7-fcdcf8559-h5pqb 1/1 Terminating 0 3h11m
lsfcluster-rhel7-fcdcf8559-xkld7 1/1 Running 0 3h11mAfter a short time, we end up with 4 new compute pods, which should contain the edits made earlier to the volumes and volumeMounts.
$ oc get pods
NAME READY STATUS RESTARTS AGE
ibm-lsf-operator-66bd9449c-5lzmx 2/2 Running 0 24h
lsfcluster-master-68f954645-j8v2v 1/1 Running 0 3h13m
lsfcluster-rhel7-6577566b87-8jsvc 1/1 Running 0 2m29s
lsfcluster-rhel7-6577566b87-fhwtt 1/1 Running 0 2m32s
lsfcluster-rhel7-6577566b87-nxkp4 1/1 Running 0 4m46s
lsfcluster-rhel7-6577566b87-ppxm9 1/1 Running 0 4m46sLet’s confirm if the shared memory has been correctly configured according to the updates made to the deployment. We now see that tmpfs is mounted to /dev/shm.
# mount |grep shm
shm on /dev/shm type tmpfs (rw,nosuid,nodev,noexec,relatime,context="system_u:object_r:container_file_t:s0:c801,c980",size=65536k)
tmpfs on /dev/shm type tmpfs (rw,relatime,seclabel)As we’ve created new deployments, it’s necessary to re-install Intel oneAPI. Note this can likely be incorporated into the pod deployment YMMV. With Intel oneAPI installed again, it’s time to re-run the MPI Hello World example, using the same steps as earlier. Eureka!
# mpirun -n 4 ./mpi_hello_world
Hello world: rank 1 of 4 running on lsfcluster-rhel7-6577566b87-8jsvc
Hello world: rank 2 of 4 running on lsfcluster-rhel7-6577566b87-8jsvc
Hello world: rank 3 of 4 running on lsfcluster-rhel7-6577566b87-8jsvc
Hello world: rank 0 of 4 running on lsfcluster-rhel7-6577566b87-8jsvcNow, let’s run the MPI Hello World example through LSF. The Intel MPI mpirun script takes care of setting the necessary variables to trigger the use of the LSF blaunch task starting mechanism. Each one of our compute pods has 4 cores. So we specify 16 (4 cores * 4 pods) job slots when submitting the MPI job to LSF.
# bhosts -w
HOST_NAME STATUS JL/U MAX NJOBS RUN SSUSP USUSP RSV
lsfcluster-rhel7-6577566b87-8jsvc ok - 4 0 0 0 0 0
lsfcluster-rhel7-6577566b87-fhwtt ok - 4 0 0 0 0 0
lsfcluster-rhel7-6577566b87-nxkp4 ok - 4 0 0 0 0 0
lsfcluster-rhel7-6577566b87-ppxm9 ok - 4 0 0 0 0 0
lsfmaster closed_Full - 0 0 0 0 0 0
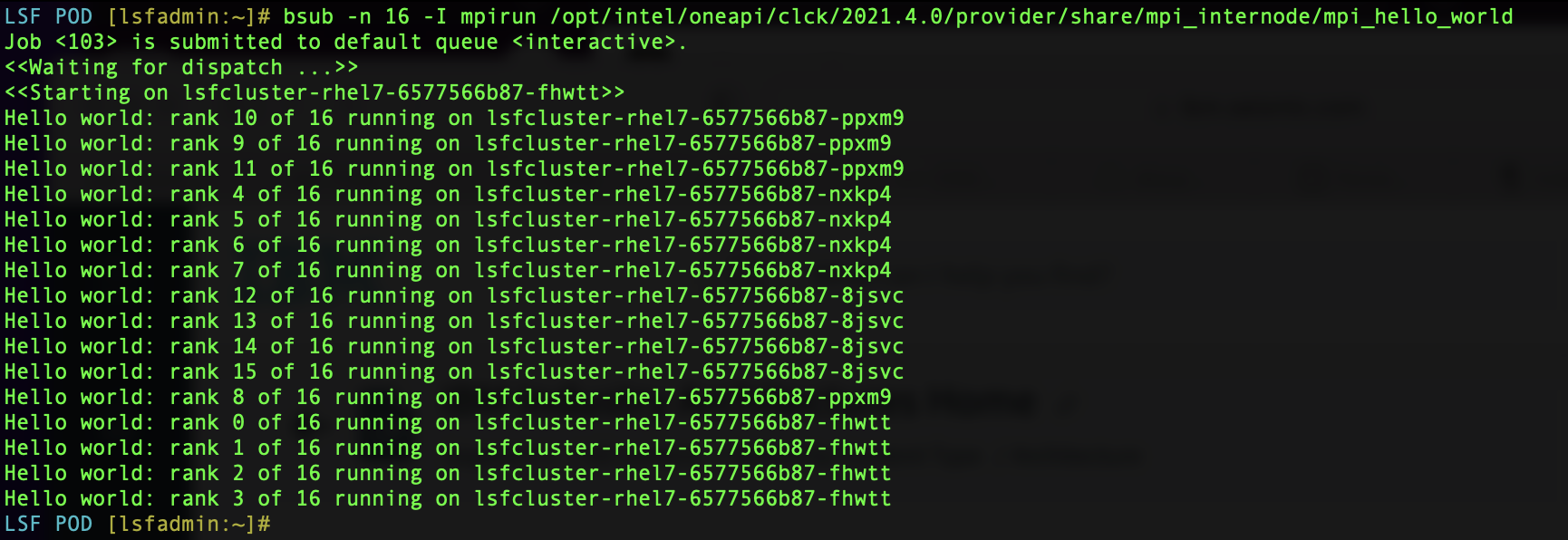
# bsub -n 16 -I mpirun /opt/intel/oneapi/clck/2021.4.0/provider/share/mpi_internode/mpi_hello_world
Job <102> is submitted to default queue <interactive>.
<<Waiting for dispatch ...>>
<<Starting on lsfcluster-rhel7-6577566b87-fhwtt>>
Hello world: rank 5 of 16 running on lsfcluster-rhel7-6577566b87-nxkp4
Hello world: rank 6 of 16 running on lsfcluster-rhel7-6577566b87-nxkp4
Hello world: rank 7 of 16 running on lsfcluster-rhel7-6577566b87-nxkp4
Hello world: rank 12 of 16 running on lsfcluster-rhel7-6577566b87-8jsvc
Hello world: rank 13 of 16 running on lsfcluster-rhel7-6577566b87-8jsvc
Hello world: rank 8 of 16 running on lsfcluster-rhel7-6577566b87-ppxm9
Hello world: rank 14 of 16 running on lsfcluster-rhel7-6577566b87-8jsvc
Hello world: rank 9 of 16 running on lsfcluster-rhel7-6577566b87-ppxm9
Hello world: rank 10 of 16 running on lsfcluster-rhel7-6577566b87-ppxm9
Hello world: rank 11 of 16 running on lsfcluster-rhel7-6577566b87-ppxm9
Hello world: rank 0 of 16 running on lsfcluster-rhel7-6577566b87-fhwtt
Hello world: rank 1 of 16 running on lsfcluster-rhel7-6577566b87-fhwtt
Hello world: rank 4 of 16 running on lsfcluster-rhel7-6577566b87-nxkp4
Hello world: rank 2 of 16 running on lsfcluster-rhel7-6577566b87-fhwtt
Hello world: rank 3 of 16 running on lsfcluster-rhel7-6577566b87-fhwtt
Hello world: rank 15 of 16 running on lsfcluster-rhel7-6577566b87-8jsvcIn summary, the LSF operator for K8s/OpenShift makes it very easy to spin up an LSF cluster for your HPC needs. For specific types of workloads, the default shared memory setting for the pods is not sufficient. There is a procedure to address this post deployment currently. And Intel MPI jobs run through LSF transparently use the blaunch task starter – as expected.
In an upcoming blog, I plan to devote a bit more time discussing the Spectrum LSF operator for K8s/OpenShift.