IBM Platform HPC V3.2: GPU Management with NVIDIA CUDA 5
IBM Platform HPC V3.2 is easy-to-use, yet comprehensive technical computing cluster management software. It includes as standard GPU scheduling, managementand monitoring capabilities for systems equipped with NVIDIA Tesla GPUs.
IBM Platform HPC V3.2 has support out of the box for NVIDIA CUDA 4.1, including a NVIDIA CUDA 4.1 software Kit. The Kit allows for simplified deployment of software in a clustered environmnet.
If your cluster is equipped with the latest NVIDIA Tesla hardware based upon the Kepler architecture, you may require NVIDIA CUDA 5. Here we discuss the steps to install a configure a IBM Platform HPC V3.2 cluster with NVIDIA Tesla Kepler hardware.
Definitions
The following capabilities in IBM Platform HPC V3.2 will be used to facilitate the deployment of NVIDIA CUDA 5. The steps detailed below will assume familiarity with IBM Platform HPC V3.2 tools.
- Cluster File Manager (CFM): This will be used to automate patching of the system boot files to perform the installation of NVIDIA CUDA 5.
- Post-Install script: This is used to trigger the execution of the system startup file on first boot post-provisioning.
Environment Preparation
It is assumed that the IBM Platform HPC V3.2 head node has been installed and that there are compute nodes equipped with NIVDIA Tesla GPUs that will be added (provisioned) to the cluster. The specifications of the example environment follow:
- IBM Platform HPC V3.2 (Red Hat Enterprise Linux 6.2 x64)
- NVIDIA® Tesla® K20c
- NVIDIA CUDA 5 (cuda_5.0.35_linux_64_rhel6.x-1.run)
Two node cluster:
- installer000 (Cluster head node)
- compute000 (Compute node equipped with Tesla K20C)
Here we fulfil the pre-requisites necessary for before provisioning the compute node(s) equipped with NVIDIA Tesla.
- The Administrator of the cluster must download NVIDIA CUDA 5 and copy to the /shared directory on the IBM Platform HPC head node. This directory is NFS mounted by all compute nodes managed by IBM Platform HPC. Note that the execute bit must be set on the CUDA package file.
# cp ./cuda_5.0.35_linux_64_rhel6.x-1.run /shared
# chmod 755 /shared/cuda_5.0.35_linux_64_rhel6.x-1.run
# ls -la /shared/cuda*
-rwxr-xr-x 1 root root 702136770 Apr 4 20:59 /shared/cuda_5.0.35_linux_64_rhel6.x-1.run- On the IBM Platform HPC head node, create a new nodegroup for nodes equipped with NVIDIA Tesla hardware. The new nodegroup template is given the name compute-rhel-6.2-x86_64_Tesla and is a copy of the built-in nodegroup template compute-rhel-6.2-x86_64.
# kusu-ngedit -c compute-rhel-6.2-x86_64 -n compute-rhel-6.2-x86_64_Tesla
Running plugin: /opt/kusu/lib/plugins/cfmsync/getent-data.sh
.
.
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/root/.ssh/authorized_keys
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/root/.ssh/id_rsa
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/opt/kusu/etc/logserver.addr
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/opt/lsf/conf/hosts
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/opt/lsf/conf/profile.lsf
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/group.merge
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/hosts.equiv
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/hosts
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/shadow.merge
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/.updatenics
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/passwd.merge
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/fstab.kusuappend
New file found: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/ssh/ssh_config
.
.
Distributing 76 KBytes to all nodes.
Sending to 10.1.1.255
Sending to 10.1.1.255
Sending to 10.1.1.255
Sending to 10.1.1.255
Sending to 10.1.1.255- Configure the CFM framework to patch the /etc/rc.local on a set of compute nodes. The following example script will check for the existence of the NVIDIA CUDA tool nvidia-smi on a node in /usr/bin. If nvidia-smi is not found in /usr/bin, the script will mount the NFS share /depot/shared to /share and will run the NVIDIA CUDA installation with the option for silent (non-interactive) installation. Note that this example will need to be altered according to your environment (IPs, CUDA package name, etc).
Filename: /etc/cfm/compute-rhel-6.2-x86_64_Tesla/etc/rc.local.append
#!/bin/sh
# If /usr/bin/nvidia-smi does not exist, then mount /shared filesystem on IBM Platform HPC # head node and run NVIDIA CUDA install with the silent option.
if [ ! -f /usr/bin/nvidia-smi ]
then
mkdir /shared
mount -t nfs 10.1.1.150:/depot/shared /shared
/shared/cuda_5.0.35_linux_64_rhel6.x-1.run -driver -toolkit -silent
fi- Create a post-installation script which will be configured to execute on a set of compute nodes. The purpose of the post-installation script is to force the execution of the updated /etc/rc.local script during the initial boot of a node after provisioning. The following example script is saved as /root/run_rc_local.sh on the IBM Platform HPC head node. Note that this script will be specified as a post-installation script in the subsequent steps.
Filename: /root/run_rc_local.sh
#!/bin/sh -x
/etc/rc.local > /tmp/runrc.log 2>&1- On the IBM Platform HPC head node, start kusu-ngedit and edit the nodegroup installer-rhel-6.2-x86_64. The following updates are required to enable monitoring of GPU devices in the IBM Platform HPC Web console.
- On the Components screen, enable component-platform-lsf-gpu under platform-lsf-gpu.
- (Select Yes to synchronise changes).
- On the IBM Platform HPC head node, start kusu-ngedit and Edit the nodegroup compute-rhel-6.2-x86_64_Tesla. The following updates are required to enable the GPU monitoring agents on nodes, in addition to the required OS software packages, and kernel parameters for NVIDIA GPUs.
- On the Boot Time Paramters screen, add the following Kernel Params (at the end of the line): rdblacklist=nouveau nouveau.modeset=0.
- On the Components screen, enable component-platform-lsf-gpu under platform-lsf-gpu.
- On the Optional Packages screen, enable the following packages: kernel-devel, gcc, gcc-c++
- On the Custom Scripts screen, add the script /root/run_rc_local.sh
- (Select Yes to synchronise changes).
- Update the configuration of the IBM Platform HPC workload manager. This is
required in order for the NVIDIA CUDA specific metrics to be taken into account.
# kusu-addhost -u Running plugin: /opt/kusu/lib/plugins/cfmsync/getent-data.sh Updating installer(s) Sending to 10.1.1.255 Sending to 10.1.1.255 Sending to 10.1.1.255 Sending to 10.1.1.255 Sending to 10.1.1.255 Setting up dhcpd service... Setting up dhcpd service successfully... Setting up NFS export service... Running plugin: /opt/kusu/lib/plugins/cfmsync/getent-data.sh Distributing 60 KBytes to all nodes. Updating installer(s) Sending to 10.1.1.255 Sending to 10.1.1.255 Sending to 10.1.1.255 Sending to 10.1.1.255 Sending to 10.1.1.255
Provision nodes equipped with NVIDIA Tesla
With the environment pre-requisites complete, the provisioning of the compute nodes equipped with NVIDIA Tesla follows. Provisioning of nodes may be done using the IBM Platform HPC Web Console, or via the kusu-addhost CLI/TUI. Here, we provision the node using the kusu-addhost CLI with the newly created nodegroup template compute-rhel-6.2-x86_64_Tesla.
Note that once nodes are discovered by kusu-addhost, the administrator must exit from the listening mode by pressing Control-C. This will complete the node discovery process.
# kusu-addhost -i eth0 -n compute-rhel-6.2-x86_64_Tesla -b
Scanning syslog for PXE requests...
Discovered Node: compute000
Mac Address: 00:1e:67:31:45:58
^C
Command aborted by user...
Setting up dhcpd service...
Setting up dhcpd service successfully...
Setting up NFS export service...
Running plugin: /opt/kusu/lib/plugins/cfmsync/getent-data.sh
Distributing 84 KBytes to all nodes.
Updating installer(s)
Sending to 10.1.1.255
Sending to 10.1.1.255
Sending to 10.1.1.255
Sending to 10.1.1.255
Sending to 10.1.1.255Monitoring nodes equipped with NVIDIA Tesla
After having provisioned all of your GPU equipped nodes, it is now possible to monitor GPU related metrics via the IBM Platform HPC Web Console. Point a supported web browser to the IBM Platform HPC head node and login as a user with Administrative privileges. The URL to be used: http://<IBM_Platform_HPC_head_node>
The IBM Platform Web Console provides a view of GPU metrics under
- Dashboard/Rack View
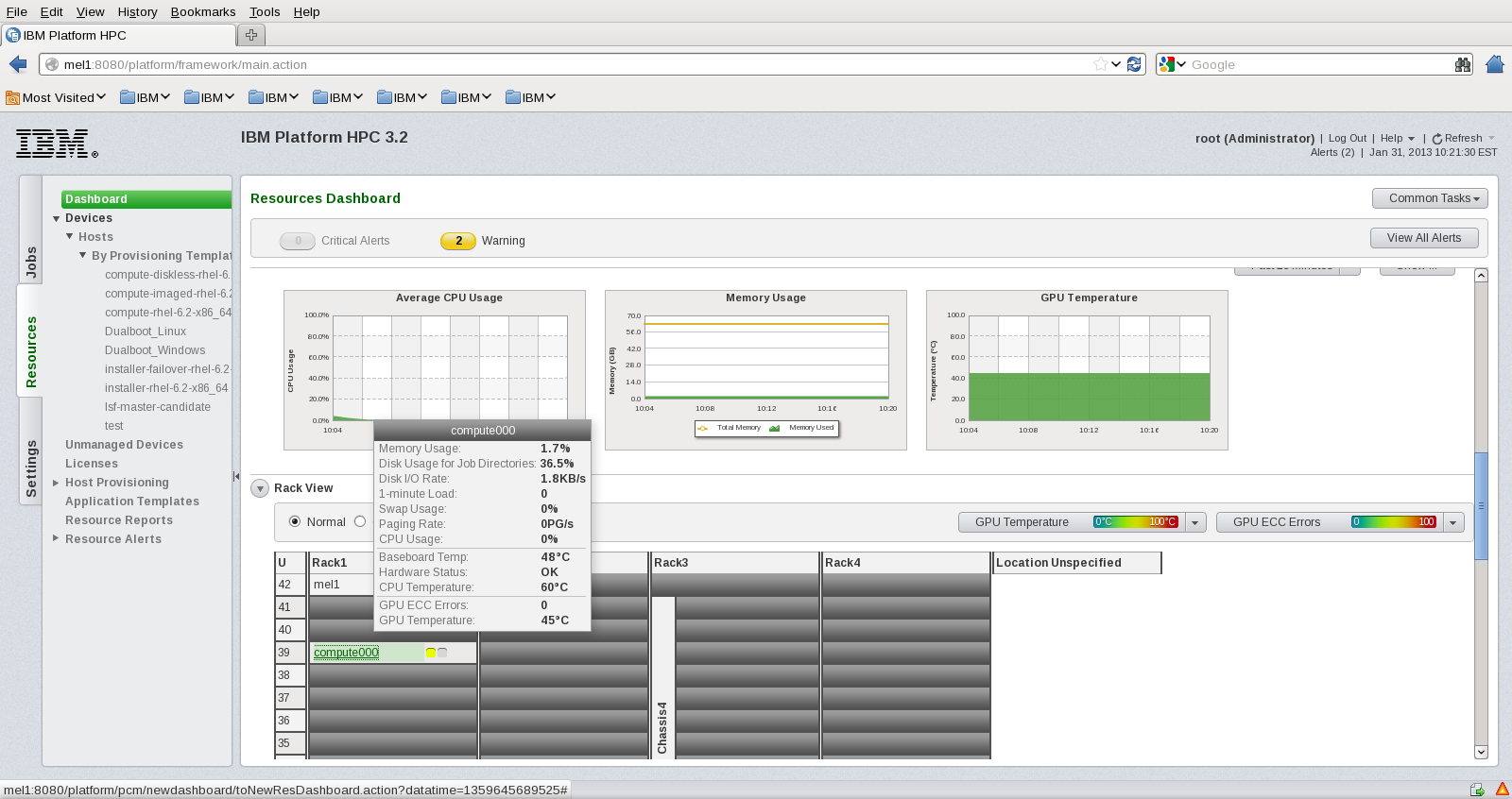
Within the Dashboard view, hover the mouse pointer over a node equipped with NVIDIA Tesla. The popup will display the GPU temperature and ECC errors.
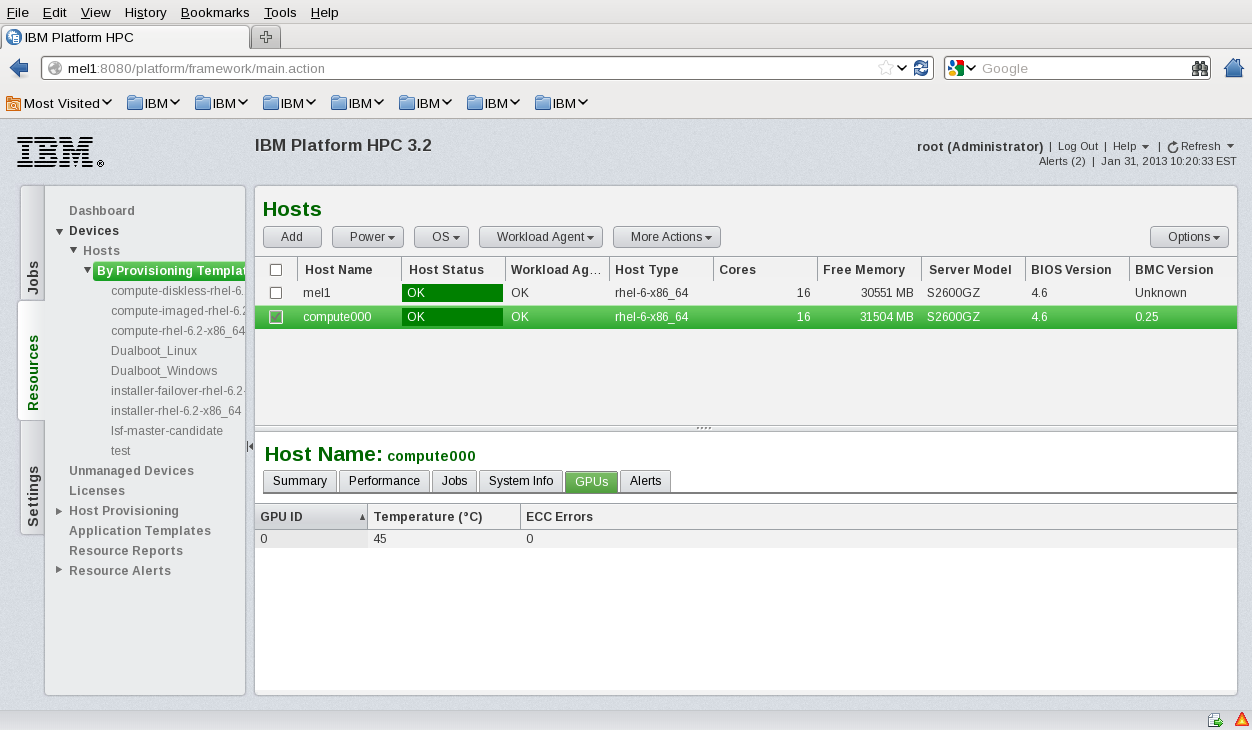
- Host List View (GPU Tab)